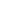罕见疾病通常难以诊断,而预防针对罕见病患者的最佳疗法对于临床医生而言也是一项巨大挑战。近日,一篇发表在国际杂志Nature Biomedical Engineering上题为“Fast and scalable search of whole-slide images via self-supervised deep learning”的研究报告中,来自美国布莱根妇女医院等机构的科学家们通过研究开发了一种深度学习算法,其或能通过自学方式来学习用于在大型病理学图像库中寻找类似病例的特征。
这种名为SISH(用于组织学的自我监督图像搜索Self-Supervised Image search for Histology)的工具就好像一种进行病理图像分析的搜索引擎,其拥有多种潜在的应用,包括识别罕见疾病并帮助临床医生确定哪些病人可能会对类似的疗法产生反应。研究者Faisal Mahmood说道,本文研究结果表明,我们的系统能帮助诊断罕见疾病并在不需要注释的前提下寻找具有类似形态模式的病例,也并不需要用于监督训练的大规模数据库;这种系统或有望改善病理学的训练、疾病亚型划分、肿瘤的鉴定仪及罕见形态学的鉴定等。
现代的电子数据库能存储大量的数字记录和参考图像,尤其是在病理学中通过整张幻灯片图像,然而每个单独的整张图像的千兆像素的大小仪及大型数据库中不断增加的图像数量意味着,对图像的搜索和检索是可能缓慢且非常复杂的,因此,其可扩展性仍然是有效使用的一个相关的障碍。为了解决这个问题,研究人员就开发了SISH,并让其自我学习相关特征,无论数据库的大小,其都能以恒定的速度找到病例学中具有类似特征的病例。
能自我学习的人工智能技术或能利用病理学图像来寻找类似的患者病例 从而帮助诊断人类罕见疾病。
图片来源:Nature Biomedical Engineering (2022). DOI:10.1038/s41551-022-00929-8
这项研究中,研究人员检测了SISH检索常见和罕见癌症的可解释疾病亚型信息的速度和能力,该算法能成功从超过2.2万张病人病例的多张完整图像的数据库中检索到相应的图像,其中有超过50种不同的疾病类型以及十几个解剖部位。其检索的速度在很多情况下超过了其它方法,包括疾病亚型的检索,尤其是当图像数据库的规模扩大到数千张图像时,即使在数据库规模扩大时,SISH也能保持恒定的搜索速度。尽管该算法存在一定的局限性,包括对内存要求较大,在大型组织切片中有限的背景意识以及被局限于单一的成像方式。总的来讲,这种算法展示了其有效检索图片的能力,而这并不依赖于存储库的大小以及不同的数据库,同时其还显示了在诊断罕见疾病类型上的熟练程度,以及作为搜索引擎识别可能与诊断相关的特定图像区域的能力,本文研究工作或许能为后期科学家们进行疾病诊断、预后和分析提供大量信息。
研究者Mahmood说道,随着图像数据库规模的不断扩大,我们希望SISH能更加容易地进行疾病的识别和诊断,我们认为这一研究领域未来重要的方向就是进行多模式的病例检索,这主要涉及利用病理学、放射学、基因组学和电子医疗记录数据来寻找相类似的病人病例。综上,本文研究结果表明,研究人员在多个任务及跨越2.2万个病例以及56种疾病亚型中评估了SISH的能力,包括基于组织切片查询的检索能力等,此外,SISH还能用于诊断人类罕见的癌症类型,对于这些疾病,可用的总体图像通常并不足以训练有监督模式的深度学习模型。(生物谷Bioon.com)